From MVP to Production: Building AI Apps in Serbian (and Why English is So Much Easier)
When developing an AI-powered app, early prototypes often look promising. But once you move from a demo or MVP (minimum viable product) to a production system, new challenges emerge – especially if your app operates in a non-English language. English-centric AI models and tools don’t always translate smoothly to less-represented languages, leading to performance gaps and unexpected issues. In this post, we’ll explore those challenges through the lens of building a real-world app in Serbian, and how our team at Positive d.o.o. confronted – and ultimately solved – them. We’ll also touch on how these issues appear in other languages, and why building in English is so much easier by comparison.
The MVP vs. Production Gap in Non-English AI
“It worked in the demo – what happened in production?” This is a common feeling when scaling an AI app beyond English. The reality is that most large language models (LLMs) and embedding models today are heavily biased toward English. They excel in English, but perform less proficiently in other languages[1]. In fact, reports indicate that OpenAI’s GPT-4 was trained on roughly 90% English content, with only a small fraction of the data in other languages[2]. Likewise, other leading models (like LLaMA or Anthropic’s Claude) had limited exposure to non-English text during training[2]. It’s no surprise then that a prototype built on these models might shine in English, yet stumble on languages that the model saw far less during training.
To quantify this gap, recent evaluations of multilingual embedding models found a clear language sensitivity: nearly all models performed best on English, with significant drops in accuracy for less-represented languages[3]. For example, one study showed embedding models handled French or Polish reasonably well, but struggled more with languages like Czech or Hungarian[3]. Another benchmarking effort tested state-of-the-art LLMs on eight languages (including low-resource ones like Tamil and Kinyarwanda) and confirmed that models consistently score higher on high-resource languages than on low-resource ones[4][5]. In short, the further you stray from English, the more an AI’s performance can degrade.
Why is production harder whe Building AI Apps in Serbian? In an MVP, you might not notice these subtleties – a small test dataset may not reveal that the model is misunderstanding Serbian idioms or missing query results in Cyrillic script. But at production scale, these issues bite. Users expect the same level of intelligence and relevancy from your app in Serbian as they would get in English, and that requires overcoming the inherent biases and blind spots of current AI models.
Case Study: Challenges of Serbian – Language and Alphabet
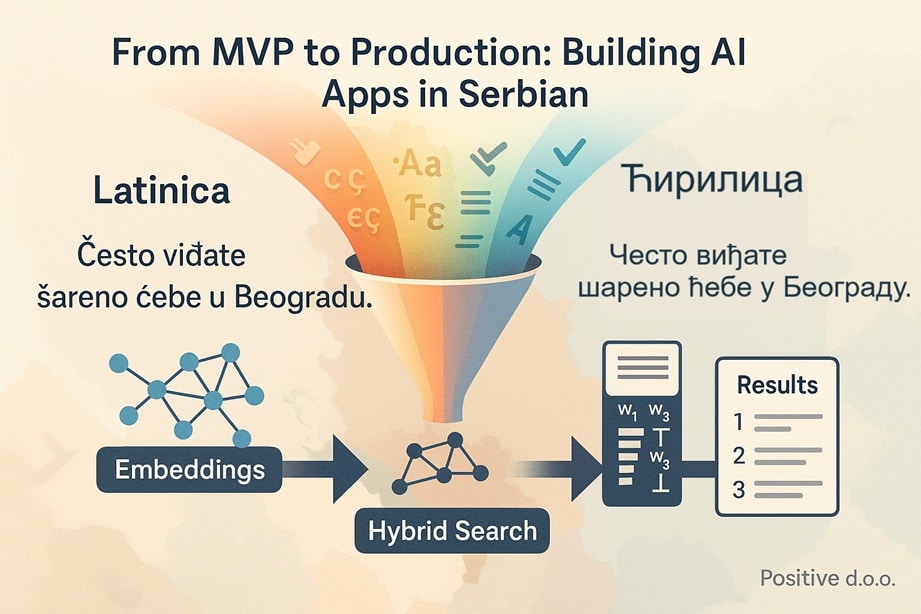
Serbian is a particularly interesting example because it presents a double challenge: it’s a less-represented language and it uses two alphabets. Serbian can be written in Latin or Cyrillic script (both are official and widely used). From a linguistic standpoint, the two scripts map almost one-to-one – but from a software standpoint, they might as well be different languages. We discovered that search and retrieval performance can vary dramatically depending on the alphabet used.
For instance, when our app indexed a collection of Serbian documents, some were in Latin script and others in Cyrillic. A naive keyword search would fail to match queries across the scripts – a user searching in Latin wouldn’t find results that were stored in Cyrillic, and vice-versa. Even Google has struggled with this: Serbian users have observed that searching Google in Cyrillic yields entirely different results than the same query in Latin[6]. On Serbian Wikipedia, searching for a show title in Latin (“Izgubljeni”) returned only a few dozen results, whereas the Cyrillic form (“Изгубљени”) yielded several hundred hits[6]. The content was the same language – Serbian – but the script mismatch meant the search engine didn’t see them as related. Wikimedia’s engineers eventually had to implement a special plugin to merge Cyrillic and Latin scripts in the search index and even perform cross-script transliteration and stemming[7] so that users can find information regardless of which alphabet they type in.
This was a lesson we took to heart at Positive. In our production system, which included a combination of OpenAI’s embedding-based semantic search and keyword search, we needed to handle the alphabet issue. Relying on pure semantics wasn’t enough; if a user’s query was in Latin script and our relevant text was in Cyrillic, even the best semantic embedding might not bridge that gap fully. And a lexical algorithm like BM25 certainly wouldn’t match “лекар” with “lekar,” even though they’re the same word “doctor” written in different scripts.
Solution – normalize or double-index? We had a few options: one was to convert everything to a single script (e.g. store and search all text in Latin only). Another was to index both versions of each document (so every text is available in Cyrillic and Latin). Serbian’s fortunate in that conversion is straightforward and lossless[8][9]. We chose to standardize our data to one alphabet internally, which immediately boosted our keyword search recall. It also helped our embeddings, since the embedding model didn’t have to handle two orthographies for the same language. (Interestingly, there are now even Serbian-specialized embedding models that explicitly support both scripts in one model[10]. This shows how important script handling is – a community-trained model called Embedić was fine-tuned to embed Serbian text whether it’s in Ћирилица or Latinica, because using a generic multilingual model wasn’t enough for top accuracy[10]. They even note that if you drop Serbian diacritic marks – writing c instead of ć, etc. – it significantly decreases search quality[11]. All these nuances matter for production.)
Beyond the alphabet, Serbian poses other typical “non-English” issues: richer morphology (e.g. search for “лекар” vs “лекари” – doctor vs doctors – should ideally find the same content, which requires stemming or lemmatization), and less training data available for the models. We had to ensure our search solution could handle inflections, either via the embedding’s semantic understanding or via a Serbian-aware text analyzer in the keyword engine. These are challenges English mostly doesn’t have (English plurals are easy and many search tools handle them by default; Serbian required a custom analyzer). It became clear that developing in Serbian demanded extra work “under the hood” that an English app might get for free.
Techniques We Applied: Hybrid Search with Pinecone
To tackle these challenges, Positive d.o.o. implemented a hybrid search strategy in our production app. This approach combined vector-based semantic search (using OpenAI’s embeddings) with traditional keyword search (BM25) in the Pinecone vector database. Why hybrid? Because semantic search is great for understanding meaning, while keyword search ensures exact matches for names, jargon, or specific terms. Each method alone has trade-offs – keyword search can miss synonyms or context, and pure semantic search might overlook precise keywords[12][13]. By combining them, we aimed to get the best of both worlds – and indeed, studies show that hybrid search yields more relevant results than either method alone[14].
Using Pinecone’s hybrid index, we indexed each document with both its dense vector embedding (for semantic similarity) and a sparse vector of token frequencies (for lexical matching). At query time, Pinecone allows blending the two signals to return results that are both semantically relevant and contain keyword overlaps with the query[15][16]. For example, if a user searched “najbolji lekar Beograd” (“best doctor Belgrade”), the semantic part could retrieve documents about top doctors in Belgrade even if wording is different, while the keyword part ensures that documents explicitly mentioning “Belgrade” and “doctor” are prioritized. We tuned the balance between semantic vs. keyword relevance to optimize results for Serbian content.
However, applying this technique wasn’t without its own hurdles. We had to generate appropriate sparse vectors for Serbian text – effectively, we needed a Serbian tokenizer and analyzer to feed Pinecone the terms. Off-the-shelf tokenizers are often English-centric; they might not handle Serbian letters or word forms correctly. We ended up leveraging an open-source Serbian analyzer (similar to those used in Elasticsearch with a Serbian locale) to break text into terms, lowercase them, and normalize diacritics. These term frequencies became our sparse vectors (essentially a BM25 representation). This ensured that the hybrid search was truly “bilingual” in the sense of handling both scripts and Serbian vocabulary.
Through hybrid search, we noticed a solid improvement in retrieval performance. Many queries that previously returned incomplete results (due to one method alone missing something) started to return the expected documents. It especially helped with proper nouns and technical terms – for instance, a query including the name of a Serbian institution in Cyrillic would now match a document where that institution was mentioned in Latin script, because the semantic embedding recognized them as the same and/or our unified script indexing had made them match lexically.
Yet, even after squeezing all we could from fancy search algorithms, we found there was one factor more important than any specific algorithm or model tweak…
The Biggest Lesson: Source Material Preparation is King
In the end, the quality and preparation of our source data had the largest impact on real-world performance. We often hear “garbage in, garbage out,” and that was absolutely our experience. After trying state-of-the-art multilingual embeddings, cross-script indexing, and hybrid retrieval, the most effective boosts to our system came from preparing the content properly for the AI to consume.
What do we mean by source material preparation? It includes all the unglamorous but critical work of cleaning, normalizing, and enriching the data before it ever goes into the model or index. For our Serbian app, this meant steps like:
- Consistent Script – As mentioned, we converted all text to one alphabet. This eliminated an entire class of search misses.
- Normalization – We made sure things like accented characters, casing, and common typos were handled. For example, we decided on a standard for Serbian diacritics and fixed any “ascii-ized” texts to use proper č, ć, š, ž, đ characters, since dropping them hurt search quality[11].
- Segmentation and Chunks – We broke documents into meaningful chunks (paragraphs or sections) for embedding, ensuring that each chunk was self-contained and topical. This way, the embedding model could more easily encode the relevant information, and our search would retrieve focused passages.
- Stemming and Synonyms – For the keyword part, we incorporated a Serbian stemming algorithm (so that lekar and lekari match) and created a small synonym map for terms we knew our users might phrase differently (e.g. common abbreviations, Anglicisms vs. Serbian words).
- Quality checks – Some source documents had mixed languages (a bit of English text or code snippets). We cleaned those or tagged them so they wouldn’t confuse the model. We also removed irrelevant boilerplate text that was showing up frequently in results (imagine every document had a footer “© Government of Serbia” – a lexical search might repeatedly surface that if not removed).
By the time we finished, our knowledge corpus was in a pristine, model-ready state. And the effect was unmistakable. The retrieval accuracy and the relevance of the answers our app could provide improved dramatically. In fact, it became clear that no matter how advanced your retrieval algorithm is, if the underlying data is inconsistent or noisy, you’ll get subpar results. This aligns with a broader truth in AI: even cutting-edge RAG (Retrieval-Augmented Generation) systems “are only as good as the data they process”[17]. As one expert succinctly put it, “the success of any RAG implementation heavily depends on the quality of data preparation and cleaning processes.”[18] We found this to be true in practice – investing time in data prep yielded more gains than hyper-tuning the model.
Positive d.o.o. embraced this insight. We shifted our focus to building robust data pipelines: integrating domain-specific knowledge, curating better training examples for the embedding (when possible), and ensuring updates to source content are reflected promptly. Essentially, we turned data preparation from a one-time task into an ongoing discipline. Once this foundation was solid, all the fancy AI layers on top could finally shine.
Other Languages, Similar Obstacles
Our focus was Serbian, but many other languages present comparable challenges in production AI systems:
- Languages with multiple scripts: Besides Serbian, languages like Hindi (Devanagari vs. Latin script), Punjabi (Gurmukhi vs. Shahmukhi), Uzbek or Kazakh (historically Cyrillic vs. Latin), and Chinese (Traditional vs. Simplified characters) all have dual writing systems. Any search or NLP on these languages must account for script variance. As we saw, one might need to merge indexes or transliterate to avoid missing half the content[6][7].
- Morphologically rich languages: Languages such as Russian, Arabic, Turkish, Hungarian, Finnish, etc., have complex morphology. A user query might be in a different form (case, gender, number) than the text in documents. English largely skirts this issue (thanks to minimal inflection), but these languages need stemming or lemmatization in search. Modern multilingual embeddings do encode some of this meaning, but for exact matching or smaller corpora, you still need language-specific processing.
- Segmenting text: Languages like Chinese, Japanese, Thai don’t use spaces to separate words, which makes tokenization non-trivial. An English-centric search system might treat an entire Chinese sentence as one big “word” unless a proper segmenter is applied. This impacts both keyword search and even embedding models (which rely on tokenizers under the hood). For production, you must incorporate a tokenization step that understands the language’s writing system.
- Low-resource data: Many languages simply lack large-scale datasets. While English AI can lean on Wikipedia, massive web crawls, and countless open texts, a language like Macedonian or Swahili has far less available. This often results in poorer pre-trained embeddings or LLM responses. It may require you to generate or translate data to augment resources, or fine-tune models on the specific domain language. As an example, even a powerful model like GPT-4 struggles more with, say, Kinyarwanda or Maori – these were likely barely present in its training[5][4].
- Cultural and domain nuances: Beyond pure language, each locale has its own idioms, context, and world knowledge. An English model might not know much about Serbian pop culture or local institutions. We sometimes had to teach the model via additional grounding data so it wouldn’t give irrelevant answers. This is less of an issue in English where the training data has covered an enormous breadth of topics.
In summary, developing AI in a non-English language is like operating with a handicap – the tools aren’t as polished for it, and you need to do a lot more legwork (data cleaning, custom processing, maybe even model fine-tuning) to reach the quality bar that English has by default.
Why Building in English Is So Much Easier
It’s worth highlighting how much easier things are when you’re building an AI application in English. Having now lived on both sides, the difference is striking:
- Model performance: As noted, most models are strongest in English. They’ve seen more English text than any other language by orders of magnitude[2]. This means out-of-the-box, they understand English queries and content very well. Nuances, slang, complex questions – there’s a good chance the model can handle it in English. In Serbian, we often hit edges where the model would produce a wrong or nonsensical answer simply because it wasn’t trained deeply on that language or would fall back to “thinking in English” structure[19].
- Tooling and libraries: The entire NLP ecosystem has an English bias. Want a ready-to-use tokenizer, a pre-trained sentiment model, a knowledge graph? The English version is a click away, while the Serbian (or other language) version may not exist or is far less mature. Many open-source search solutions default to English analyzers (which, for example, don’t know how to lowercase Unicode letters like Đ properly or how to handle Cyrillic word boundaries). When building our English demo, we hardly had to configure the search – it just worked. For Serbian, we spent days on configuring analyzers, stop-word lists, custom dictionaries, etc.
- Data availability: Need to train or fine-tune something? For English, you can likely find a relevant dataset or just scrape the web (which is dominated by English content). For Serbian and many languages, data is the biggest bottleneck. We ended up creating synthetic data or translating some English materials because there was no native corpus for certain tasks. This extra data preparation is time-consuming.
- Community and support: The forums, docs, and community help for AI problems skew English. We encountered very specific issues (like how to handle Latin vs Cyrillic in embeddings) where virtually no existing discussion was available. With an English app, chances are high someone has solved a similar issue (because so many people build in English first). Essentially, fewer wheels need reinventing.
- User expectations: English-speaking users are spoiled by Google, Alexa, GPT-4, etc., which work fantastically in English. If your app is English-first, you’re competing on quality but at least the tech foundations are solid. For other languages, user expectations might be lower (because they’ve never had a truly great AI assistant in their language) – but meeting your own expectations is harder because the gap between what’s possible in English and what’s currently achievable in, say, Serbian, is noticeable. We had to accept that some things (like perfectly fluent GPT-style generation) would lag behind English capabilities, at least until multilingual models improve.
To put a number on it, developing our Serbian AI system felt easily twice as hard as an equivalent English system – not because of the app’s logic, but because of all the language-related hurdles. And for more obscure languages or those with complex scripts, that multiplier could be even higher. A Brookings report recently noted that AI tools trained on internet data might widen the gap between “data-rich” languages and the rest[20]. We clearly see this in development effort. English is data-rich and tool-rich; most other languages still require extra sweat to reach parity.
Concluding Thoughts
Our journey with Positive’s Serbian AI app was a crash course in the often overlooked realities of multilingual AI development. Going from a promising pilot to a successful production system meant tackling language-specific issues head-on: the quirks of alphabets, the scarcity of language data, and the need for bespoke solutions like hybrid search and custom preprocessing. We learned that while advanced techniques (embeddings, vector databases, hybrid retrieval) are powerful, they only fulfill their potential when built on a foundation of well-prepared data.
The good news is that each challenge can be solved – and the solutions make your system robust not just for Serbian, but adaptable to other languages down the line. By investing in data preparation, language normalization, and hybrid techniques, we turned a seemingly “hard” language into a success story for our AI app. In doing so, we also gained a deeper appreciation for the incredible advantage of working in English – and a motivation to help bring other languages up to speed in the AI world.
At Positive d.o.o., we ultimately delivered a production-ready app that performs confidently in Serbian, providing users with accurate search and AI-generated answers across both Latin and Cyrillic content. The path wasn’t easy, but it was rewarding – not only did we solve the immediate problem, we also contributed knowledge and experience that can benefit multilingual AI projects in the future. The next time you see an AI that “just works” in your native language, remember the unseen effort that likely went into making it as good as its English counterpart. And if it isn’t good yet – well, we hope our story offers some guidance on how to get there.
References:
- Performance disparities in multilingual AI models[3][4]
- Script differences affecting search results (Serbian Latin vs Cyrillic)[6][7]
- Specialized solutions for Serbian language (embedding models and search analyzers)[10][11]
- Pinecone hybrid search combining semantic vectors with BM25 keywords[14][15]
- Importance of data preparation in retrieval-based systems[18][17]
- English vs. other language training data and biases in LLMs[1][2]
[1] [2] [19] Limitations of Language Models in Other Languages
https://www.simultrans.com/blog/limitations-of-language-models-in-other-languages
[3] OpenAI vs Open-Source Multilingual Embedding Models | by Yann-Aël Le Borgne | TDS Archive | Medium
https://medium.com/data-science/openai-vs-open-source-multilingual-embedding-models-e5ccb7c90f05
[4] [5] LLM benchmarking leaderboard: Languages, creativity and tasks
https://www.rws.com/blog/llm-benchmarking-leaderboard-languages-creativity-tasks
[6] [7] [8] [9] Confound it!—Supporting languages with multiple writing systems – Wikimedia Foundation
https://wikimediafoundation.org/news/2018/03/12/supporting-languages-multiple-writing-systems
[10] [11] djovak/embedic-base · Hugging Face
https://huggingface.co/djovak/embedic-base
[12] [13] [14] [15] [16] Introducing the hybrid index to enable keyword-aware semantic search | Pinecone
https://www.pinecone.io/blog/hybrid-search
[17] [18] Advanced RAG Techniques: Mastering Data Cleaning & Preparation for Intelligent Systems | by Vijay Choubey | Aug, 2025 | Medium
[20] How language gaps constrain generative AI development | Brookings
To learn more about my AI journey, read my posts
Share


